Vibe coding is everywhere. But can you tell when a website was built by prompting AI instead of writing code? I built VibeCheck to answer that question.
A friend sent me his new startup's landing page last month. Looked stunning — dark theme, smooth animations,
glassmorphic cards, the whole nine yards. I opened DevTools out of curiosity and found a data-v0-t
attribute sitting right there in the markup. The entire thing was scaffolded with v0. He hadn't written a single line of frontend code.
No judgment — honestly, the site looked great. But it got me thinking. If I could spot that in 10 seconds by poking at the DOM, what other fingerprints are these AI tools leaving behind? And could you automate the detection?
Turns out, you can. So I built VibeCheck.
Wait, what's "vibe coding"?
If you haven't come across the term yet — vibe coding is when you build a website (or app, or feature) mostly by prompting AI tools. Sometimes that's specialized tools like v0, Bolt.new, Lovable, or Cursor. Sometimes it's just straight-up ChatGPT, Claude, or Gemini — paste the output into a file, fix what's broken, ship it. You describe what you want, the AI generates the code, you tweak it a bit, deploy, done.
It's gotten really good. I've seen people ship MVPs in a weekend that would've taken weeks to build from scratch. And for prototyping, it's genuinely amazing.
But there's a flip side that doesn't get talked about enough.
When someone submits a portfolio full of AI-generated sites during a hiring process, that's a problem. When a freelancer charges ₹2L for a "custom-built" website that was actually prompted in Bolt.new (or copy-pasted from a Claude conversation) in an afternoon, the client deserves to know. When a site skips accessibility, SEO fundamentals, and proper error handling because the AI didn't think of it — well, users pay the price.
I wanted a way to check. Not to shame anyone (I use AI tools too), but simply to know.
What already existed — and why it wasn't enough
I looked around before building anything, obviously. Found a couple of Chrome extensions — one checks for purple gradients and emoji density (seriously), another does some basic HTML analysis but gives you a binary "likely/unlikely" with no explanation of why.
Then there's the AI text detector space — GPTZero, Originality.ai, etc. Those are great for detecting AI-written essays, but they only look at text content. They won't tell you that a site has 18 levels of DOM nesting, shadcn CSS variables everywhere, and Vercel's default caching headers.
Nothing combined structural analysis + content heuristics + deployment signals into one tool. And nothing was open source, so you couldn't even see what rules it was using.
So what does VibeCheck actually do?
You give it a URL. It does the following (all automated):
- Fetches the page — and if Cloudflare blocks the request, it spins up a headless browser with Playwright as a fallback
- Crawls up to 6 internal pages (follows links on the same domain)
- Pulls linked stylesheets and JS files — because a lot of signals hide in external assets, not in the HTML itself
- Runs everything through 9 detection categories
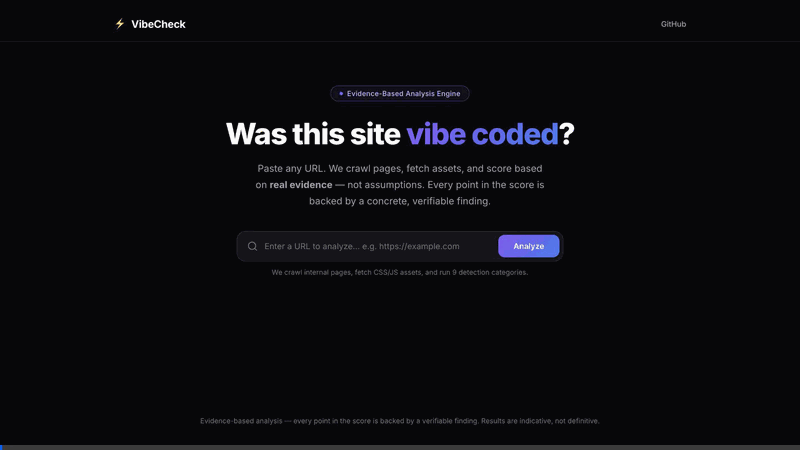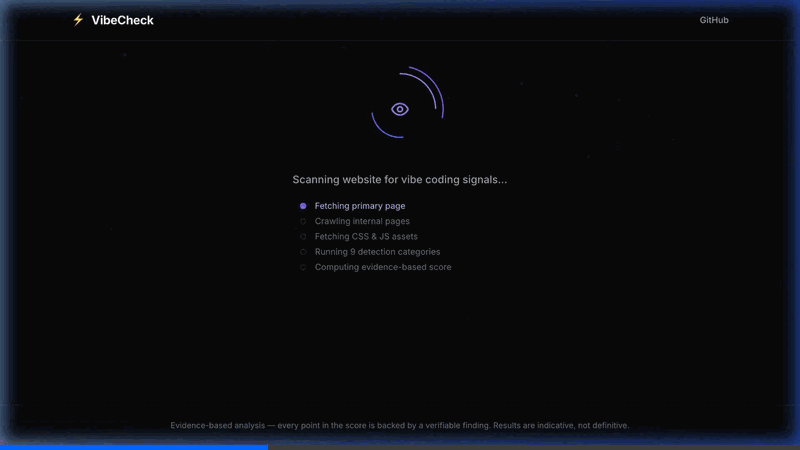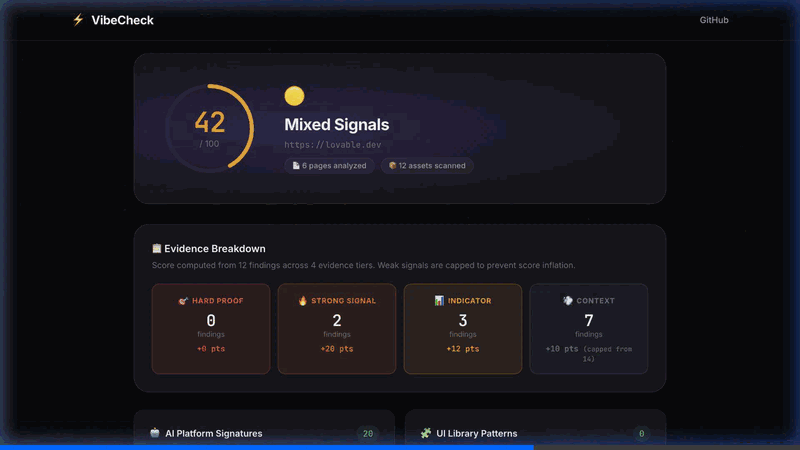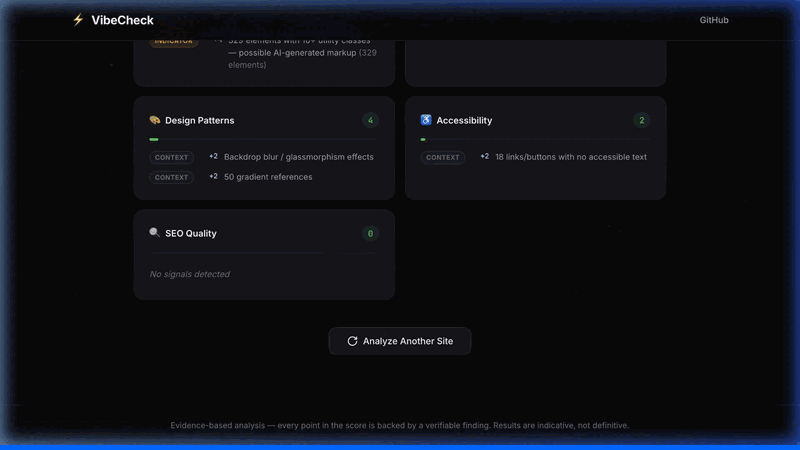
- Spits out a score from 0 to 100, with a breakdown of every finding
The important bit: every point in the score maps to something concrete. If the tool says 72, you can scroll through and see exactly which signals were found, on which page, and how confident the detection is. No black box.
Scoring works like this:
| Score | What it means |
|---|---|
| 🟢 0–25 | Probably human-crafted |
| 🟡 26–50 | Mixed — hard to tell |
| 🟠 51–75 | Likely vibe coded |
| 🔴 76–100 | Almost certainly vibe coded |
The 9 things it checks
I'll keep this concise. Each category looks for specific, verifiable patterns:
🤖 AI Platform Signatures — This is the most direct evidence. v0 leaves data-v0-t attributes in
the HTML. Lovable and GPTEngineer inject references into the source. Bolt.new has its own markers. Some tools add
<meta generator> tags. If these exist, it's pretty much game over — that's hard proof.
🧩 UI Library Patterns — AI tools default to shadcn/ui more than anything else. VibeCheck looks for the
telltale class combos (rounded-md border bg-background), Radix UI data attributes, shadcn-specific CSS
variables like --radius and --ring, and Lucide icon SVGs.
⚡ Framework Detection — Next.js markers (__next, _next/static), Vite module scripts,
React/Nuxt/Astro/SvelteKit traces. On its own this means nothing — tons of developers use Next.js. But Next.js +
shadcn + Vercel is the vibe coding stack, and the tool picks up on that combination.
📝 Content Signals — Generic marketing copy has a pattern. If your site says "Transform your workflow" and "Revolutionize your business" and has 26 "Get Started" buttons, that's a signal. Same with stock image CDNs (Unsplash URLs, Pexels embeds) and placeholder text that never got replaced.
🔬 Code Quality — DOM nesting depth is a surprisingly good indicator. AI-generated markup tends to be deeply
nested (18+ levels isn't uncommon). High Tailwind utility-class density is another — elements with 10+ classes each.
Also checks for those perfectly organized AI-style comments: <!-- Hero Section -->,
<!-- Features Grid -->. Real developers rarely comment that neatly, let's be honest.
🚀 Deployment Signals — Checks response headers and DNS for Vercel, Netlify, Railway. Also checks if
robots.txt and sitemap.xml exist. Vibe-coded projects almost never set these up because
the AI doesn't think about it and most people don't know to ask.
🎨 Design Patterns — backdrop-blur everywhere (glassmorphism), gradient overuse, the classic hero
→ features grid → testimonials → CTA layout that every AI tool generates. Card grids, neon glow effects.
♿ Accessibility — Missing alt text, no ARIA labels, broken heading hierarchy, missing form labels. AI tools are getting better at this, but they still skip a lot of the basics.
🔍 SEO — Missing or generic titles, no meta descriptions, multiple <h1> tags on one page,
no Open Graph tags. Pretty common in AI output because SEO requires intentionality.
Not all signals are equal (the tier system)
This was something I spent a lot of time on. Early versions of the tool would flag a site as "probably vibe coded" just because it used Tailwind and was on Vercel. That's obviously wrong — plenty of legitimately hand-coded projects use that stack.
So I built a 4-tier evidence system:
| Tier | Points | Cap | Example |
|---|---|---|---|
| 🔴 Definitive | 25 pts | None | v0.dev data attributes in HTML |
| 🟠 Strong | 10 pts | 40 | shadcn/ui class patterns detected |
| 🟡 Moderate | 4 pts | 25 | Generic marketing phrases |
| ⚪ Weak | 2 pts | 10 | Deployed on Vercel |
The caps are important. Seven weak signals can't push a score past 10 points, no matter how many you find. But one definitive finding (an actual v0 data attribute) is worth 25 points on its own. This way, a legitimate Next.js/Vercel site doesn't get unfairly flagged, but actual AI fingerprints get properly weighted.
Under the hood
The tech stack is straightforward — I didn't want it to be complicated for people to self-host or contribute to:
- Python + Flask for the server and API endpoint
- BeautifulSoup + lxml for HTML parsing
- Playwright for headless browser fallback (some sites have Cloudflare protection that blocks regular requests)
- Vanilla HTML/CSS/JS for the frontend — yes, no React. I wanted it simple
One thing I want to emphasize: no AI is used in the detection. The whole analyzer is plain heuristic pattern matching. The detection engine is a single Python file (~1,000 lines). Every rule is readable, every weight is configurable. I didn't want this to be another black box.
The analysis flow:
URL submitted
↓
Fetch page (requests first, Playwright if blocked)
↓
Discover & crawl internal pages (≤6)
↓
Fetch linked CSS/JS assets (≤10)
↓
Run 9 detection categories
↓
Compute tiered score
↓
Return JSON with score + all evidence
A few things I learned along the way
AI code has a "smell," and it's the combination that gives it away. No single signal is definitive (except platform-specific markers). But when you see Next.js + shadcn/ui + Vercel + 18-level DOM nesting + generic copy + missing robots.txt + glassmorphism on every card — you know. Individually, each of those is fine. Together, the pattern is unmistakable.
False positives are unavoidable. A well-known SaaS company using shadcn/ui legitimately will trigger some signals. That's by design — the tier system keeps it in the "Mixed Signals" range unless there's stronger evidence. I've tuned the weights a lot, but it's an ongoing process. If you run it against your own (genuinely hand-coded) site and it scores high, I'd genuinely like to know — that helps me improve the heuristics.
AI tool output is evolving fast. v0's output six months ago was way more obvious than what it produces now. Some tools have started cleaning up their markers. The heuristics need to keep pace, which is partly why I made the whole thing open source — more eyes on it, more rules getting added.
Static analysis only goes so far. VibeCheck can't execute full client-side JS in a meaningful way. SPAs that render everything dynamically will show fewer signals. Playwright helps with the initial load, but there's a ceiling to what you can detect without something more sophisticated. That's on the roadmap, eventually.
Try it
It's on GitHub — MIT licensed, free to use.
Getting it running locally takes about 2 minutes:
git clone https://github.com/ashish-jabble/vibe-check.git cd vibe-check python3 -m venv venv source venv/bin/activate pip install -r requirements.txt python app.py
Then open http://localhost:5000, paste a URL, and see what comes back.
There's also a JSON API if you want to integrate it into something:
curl -X POST http://localhost:5000/api/analyze \
-H "Content-Type: application/json" \
-d '{"url": "https://example.com"}'
What I want to build next
Some things I'm thinking about (PRs welcome, by the way):
- A browser extension that shows a quick vibe score while you're browsing
- Batch analysis — paste a list of URLs and get a report
- Tracking score changes over time for a given site (interesting for portfolio audits)
- Adding detection rules for newer tools — Windsurf, Replit Agent, and better fingerprinting for code generated by ChatGPT, Claude, and Gemini
- Maybe a public hosted version with rate limiting, though self-hosting is always going to be an option
If you work in hiring, client services, or QA and find this useful — or if you think a detection rule is unfair or missing something — I'd like to hear about it. Open an issue or shoot me a message.
Again: this isn't about dunking on vibe coding. I use AI tools in my own workflow. But when the question is "did a human actually build this?" — whether for hiring, for client work, or just for curiosity — there should be a way to get a straight answer backed by real evidence.
That's what VibeCheck does.